Autoscaling en Kubernetes
El autoescalado es una de las características más potentes de Kubernetes, permitiendo que tus aplicaciones se adapten dinámicamente a la carga de trabajo. En esta lección nos centraremos en el Horizontal Pod Autoscaler (HPA).
Introducción
Imagina que tienes una tienda online. Durante la noche tienes pocos visitantes, pero en el Black Friday el tráfico se dispara. Si tienes una infraestructura estática, o pagas de más por recursos que no usas de noche, o tu sitio se cae en el pico de tráfico.
Aquí es donde entra el Autoscaling. Kubernetes puede aumentar o disminuir automáticamente el número de réplicas de tus Pods basándose en métricas como el uso de CPU o memoria.
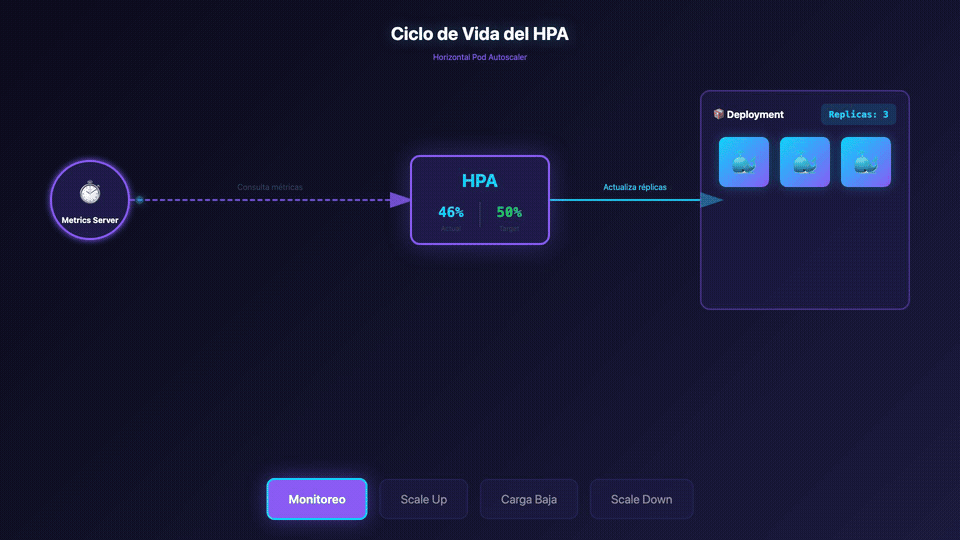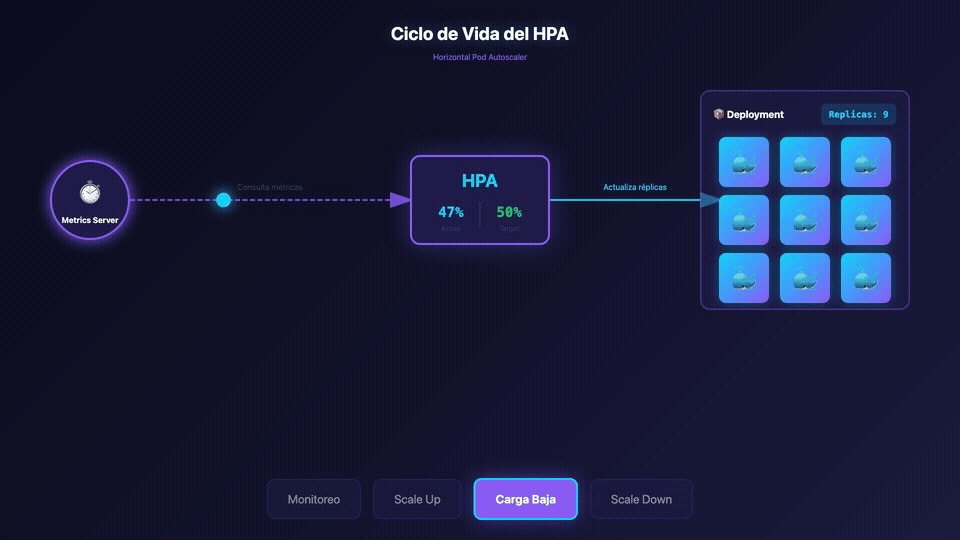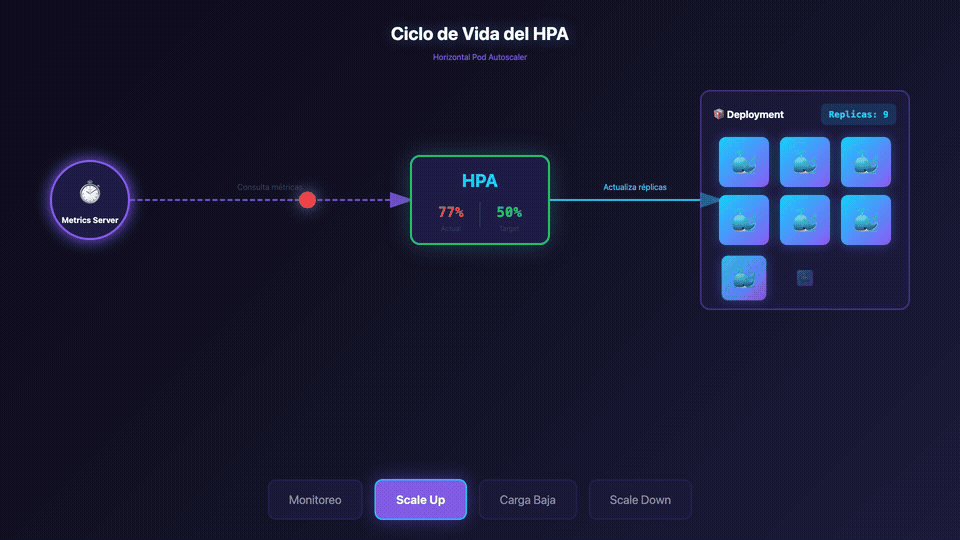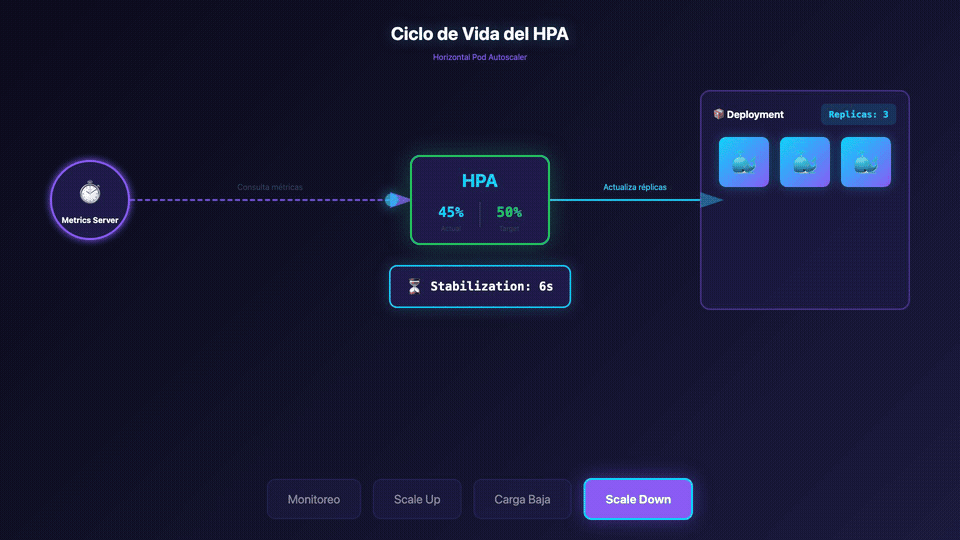
Conceptos Fundamentales
¿Qué es el HPA (Horizontal Pod Autoscaler)?
El HPA escala el número de Pods en un replication controller, deployment, replica set o stateful set basándose en la utilización de CPU observada (o, con soporte de métricas personalizadas, en otras métricas de la aplicación).
- Escalado Horizontal: Añadir más Pods (máquinas/contenedores) al pool.
- Escalado Vertical: Añadir más recursos (CPU/RAM) a los Pods existentes (esto lo hace el VPA, que veremos en otra lección junto con KEDA).
- Cluster Autoscaler: Ajusta el número de nodos en el clúster basándose en la demanda de recursos.

Requisitos Previos
Para que el HPA funcione, necesitas tener el Metrics Server instalado en tu clúster. Este componente se encarga de recolectar las métricas de uso de recursos de los contenedores.
Puedes verificar si está funcionando con:
kubectl top nodes
kubectl top pods
Ejemplo Práctico: HPA con la API Quotes
Para este ejemplo utilizaremos una aplicación real: la API de Citas Célebres del repositorio pabpereza/quotes. Esta API REST está construida con FastAPI y ya incluye probes de health check, lo que la hace perfecta para demostrar el autoescalado en Kubernetes.
📦 Todos los manifiestos YAML están disponibles en la carpeta
deploy/del repositorio.
1. Desplegar la aplicación
Primero desplegamos la aplicación con su Deployment y Service. Observa cómo definimos requests de CPU y memoria, que son esenciales para que el HPA pueda calcular los porcentajes de uso.
Crea un archivo deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: quotes-deployment
labels:
app: quotes
spec:
replicas: 3
selector:
matchLabels:
app: quotes
template:
metadata:
labels:
app: quotes
spec:
containers:
- name: quotes
image: pabpereza/quotes
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /probes/health
port: 80
initialDelaySeconds: 10
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /probes/ready
port: 80
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
memory: "1024Mi"
---
apiVersion: v1
kind: Service
metadata:
name: quotes-service
spec:
selector:
app: quotes
ports:
- protocol: TCP
port: 8080
targetPort: 80
type: ClusterIP
Puntos clave del Deployment:
resources.requests: Define los recursos mínimos que necesita cada Pod (100m CPU, 256Mi RAM). El HPA usa estos valores como referencia.livenessProbeyreadinessProbe: La API expone endpoints en/probes/healthy/probes/readypara que Kubernetes sepa cuándo el Pod está sano y listo.replicas: 3: Iniciamos con 3 réplicas, pero el HPA ajustará este número dinámicamente.
Aplica el manifiesto:
kubectl apply -f deployment.yaml
2. Crear el Horizontal Pod Autoscaler
Ahora configuramos el HPA. Este ejemplo es más avanzado que el típico ejemplo de documentación, ya que escala basándose en CPU y memoria, e incluye una configuración de comportamiento de desescalado.
Crea un archivo hpa.yaml:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: quotes-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: quotes-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
# Reducimos el periodo de cooldown de 5 a 3 minutos
stabilizationWindowSeconds: 180
policies:
- type: Percent
value: 100
periodSeconds: 15
Configuración explicada:
minReplicas: 3: Mantiene siempre al menos 3 Pods para alta disponibilidad.maxReplicas: 10: Límite máximo para evitar un escalado descontrolado.metrics: Escala si la CPU o la memoria superan el 50% de los requests definidos.behavior.scaleDown: Configura el comportamiento al desescalar:stabilizationWindowSeconds: 180: Espera 3 minutos (en lugar de 5) antes de reducir réplicas.- La política permite reducir hasta el 100% de las réplicas excedentes cada 15 segundos.
Aplica el HPA:
kubectl apply -f hpa.yaml
Truco de examen: también se puede crear un HPA básico (solo CPU) de forma imperativa con
kubectl autoscale deployment quotes-deployment --min=3 --max=10 --cpu-percent=50. Para configuraciones con varias métricas obehavior, como la de arriba, necesitarás el YAML.
Verifica el estado del HPA:
kubectl get hpa quotes-hpa
Deberías ver algo como TARGETS: 12%/50%, 8%/50% (CPU y memoria).
3. Generar Carga
El repositorio incluye un script de prueba de carga usando k6. Este script simula usuarios reales que consultan citas, crean usuarios y autentican tokens.
Puedes ejecutar la prueba de carga con:
# Primero, expón el servicio (por ejemplo, con port-forward o Ingress)
kubectl port-forward svc/quotes-service 8080:8080 &
# Ejecuta k6 con el script de stress test
k6 run https://raw.githubusercontent.com/pabpereza/quotes/main/deploy/stress-test.js
O genera carga manualmente con un contenedor:
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://quotes-service:8080/quotes; done"
4. Observar el Escalado
Observa cómo reacciona el HPA en tiempo real:
kubectl get hpa quotes-hpa -w
Verás algo similar a:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
quotes-hpa Deployment/quotes-deployment 12%/50%, 8%/50% 3 10 3 1m
quotes-hpa Deployment/quotes-deployment 85%/50%, 45%/50% 3 10 3 2m
quotes-hpa Deployment/quotes-deployment 85%/50%, 45%/50% 3 10 6 3m
quotes-hpa Deployment/quotes-deployment 42%/50%, 32%/50% 3 10 6 4m
También puedes ver el estado detallado:
kubectl describe hpa quotes-hpa
5. Detener la carga
Si detienes el generador de carga (Ctrl+C), verás que después del periodo de estabilización (3 minutos en nuestra configuración), el número de réplicas volverá a 3 (el mínimo configurado).
Conclusiones
El HPA es esencial para mantener la disponibilidad y el rendimiento de tus aplicaciones en Kubernetes sin intervención manual, optimizando al mismo tiempo el uso de recursos y costes.
Recuerda:
- Necesitas Metrics Server instalado en tu clúster.
- Debes definir Requests y Limits en tus Pods para que el HPA pueda calcular los porcentajes correctamente.
- Configura múltiples métricas (CPU y memoria) para un escalado más inteligente.
- Ajusta el comportamiento de desescalado para evitar fluctuaciones innecesarias.
- Incluye probes de health y readiness para que Kubernetes gestione correctamente el tráfico durante el escalado.
Recursos Adicionales
- Repositorio de ejemplo: pabpereza/quotes - API completa con manifiestos de Kubernetes
- Carpeta deploy/ con todos los manifiestos - Deployment, HPA, Ingress y test de carga
- Documentación oficial de Kubernetes sobre HPA
- Metrics Server en GitHub
- k6 - Herramienta de pruebas de carga
- Lista de vídeos en Youtube: Curso Kubernetes